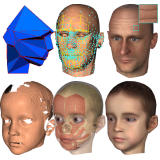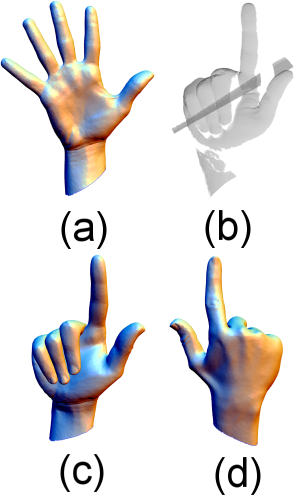

(a) Input template
(b) Range scan data
(c) Fit result front
(d) result backside (Note, backside had no scan.)
(e) Woman fit result.
Color code shows approximated geodesic distance from a marker on the right elbow.
Template Deformation for Point Cloud Fitting
Carsten Stoll, Zachi Karni, Christian Roessl, Hitoshi Yamauchi and Hans-Peter Seidel, ``Template Deformation for Point-Cloud Fitting,'' Proc. IEEE/Eurographics Symposium on Point-Based Graphics 2006, pp.27-35
Abstract: The reconstruction of high-quality surface meshes from measured data is a vital stage in digital shape processing. We present a new approach to this problem that deforms a template surface to fit a given point cloud. Our method takes a template mesh and a point cloud as input, the latter typically shows missing parts and measurement noise. The deformation process is initially guided by user specified correspondences between template and data, then during iterative fitting new correspondences are established. This approach is based on a Laplacian setting for the template without need of any additional meshing of the data or cross-parameterization. The reconstructed surface ts to the point cloud while it inherits shape properties and topology of the template. We demonstrate the effectiveness of the approach for several point data sets from different sources.
Easy abstract:
Range scanned data usually has noise and holes. It is not so easy to reconstruct a complete mesh from such scanned data. Sometimes you can not scan some part of the object. For example, the hand model has only front side scan in the Figure (b). But non-scanned backside part is inherited from the template model and the scanned part is fit to the data. This makes complete hand model (Figure (a)-(d)). Our method is first considered as human and animals posing. But then we find this method is more general and can be apply to semantically similar objects. (Here, semantically similar is a tricky word. Like quadruped animals are somehow similar. A notebook computer and a penguin are, I may say, not semantically similar, but we can discuss as they have same topology or something.)
Laplacian mesh deformation is basically not rotational invariant (we need some definitions and discussions what does it really means, if you want to know, please look at the papers, e.g., Olga Sorkine's EG2005 tutorial). Our approach approximate the local frame via the same Laplacian matrix with interpolation represented by quaternion (We use the method of EG2005 Zayer et. al). Our contribution is introducing scaling and local frame rotation, and fitting with near points search. Without them, problems of self intersection and candy lapping easily break the models.
We use the same Laplacian matrix again and again: to deform the mesh, to interpolate quaternion, and to interpolate scale of the mesh (not measure the scale part, the measure part is done with Dijkstra algorithm). So, the foundation of this method is this Laplacian matrix and you can find this method is so versatile. We did not say why we use the same foundation only, but we think mathematically this is beautiful and somehow we try to keep that. In our research, we apply other different methods to improve this (e.g., multi-resolution approach, random sampling, and etc.), however, our proposed method is still better in most of the case as long as we know. Of course, our method is the simplest. Therefore, our implementation becomes simpler.