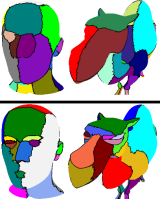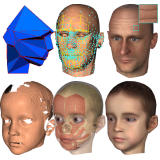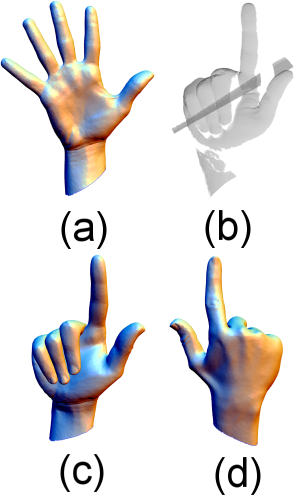

(a) Input template
(b) Range scan data
(c) Fit result front
(d) result backside (Note, backside had no scan.)
(e) Woman fit result.
Color code shows approximated geodesic distance from a marker on the right elbow.
Template Deformation for Point Cloud Fitting
Carsten Stoll, Zachi Karni, Christian Roessl, Hitoshi Yamauchi and Hans-Peter Seidel, ``Template Deformation for Point-Cloud Fitting,'' Proc. IEEE/Eurographics Symposium on Point-Based Graphics 2006, pp.27-35
Abstract: The reconstruction of high-quality surface meshes from measured data is a vital stage in digital shape processing. We present a new approach to this problem that deforms a template surface to fit a given point cloud. Our method takes a template mesh and a point cloud as input, the latter typically shows missing parts and measurement noise. The deformation process is initially guided by user specified correspondences between template and data, then during iterative fitting new correspondences are established. This approach is based on a Laplacian setting for the template without need of any additional meshing of the data or cross-parameterization. The reconstructed surface ts to the point cloud while it inherits shape properties and topology of the template. We demonstrate the effectiveness of the approach for several point data sets from different sources.
Easy abstract:
レンジスキャンなどのスキャンデータには通常ノイズや穴などがあります. また,完全に隠れている部分は通常スキャンできません. たとえば,ここでの手のモデルのスキャンデータ (b) では指を完全にスキャンすることはできません. この図では一方向からのスキャンしか利用していないので, 後方にあたる手の甲部分を点群のみから再構成することも困難です. しかし,template を用いた我々の方法では, 穴の部分やスキャンできなかった部分を template の deformation により補間するため,完全なモデルを再構成することができます(図(a)-(d)). 最初,我々はこれを人間や動物のポージングに利用することを考えました. 後に我々はこの方法がまったく同じ人間や動物でなくても「意味的に似ている」 物体ならば再構成に利用可能であることに気がつき, その方向で手法を開発することにしました. (ここで,「意味的に似ている」という言葉は定義が難しい言葉です.たとえば, 四足動物という意味ではらくだと馬は意味的に似ていると言うことができると思います. ただし,ペンギンとノートブックコンピュータはどうかというと難しいです. もしかしたらトポロジが同じものにはなる可能性はあります. すると意味的に似ていると言えるかもしれません. しかし,これはかなり難しいです.)
Laplacian mesh deformation では回転に関しては invariant を保つことができません. (この詳しい意味も簡単ではないのですが,論文や参考文献にて議論されています. たとえば,Olga Sorkine's EG2005 の論文などを参考にして下さい.) 我々の方法では,各対応点における local frame の回転とスケールを計測によって予測し,deformation に利用する Laplacian matrix と同じ matrix により補間を行い,その情報に従って deformation を行う部分が新しい部分です.これを導入しないと,簡単に self intersection や,candy lapping などの問題が発生し,モデルのポーズの再構成は困難です. local frame の Laplacian による補間は EG2005 の Zayer et. al の論文によります.また,点群の情報を用いて, より正確な fitting も行います.
提案した方法では,一つの Laplacian matrix を何度も様々な方法に応用していることが興味をひくかもしれません.local frame 補間,scale 補間,deformation は全て同じ framework で行なわれています.(ただし scaling の measure だけは Dijkstra 法を使っています.) このように一つの framework に拘るのはなぜかと尋ねられても,それが最良かどうかは確かにわかりません. しかし,一つの数学的基礎でほとんどできるということは, 我々は単純で美しいと考えています. 数学的な興味からという答えがそこにはあります. 研究の過程で我々は他の手法,Multi-resolutin 解析,random sampling なども試してみましたが, 我々の手法でほとんどの場合に同程度か良い結果を得ることができました. それならば単純な方が良いと考えます. これによる恩恵は実装が簡単になるということもあります. また,私は Laplacian matrix がこれほど様々な問題に応用できるものだということを今回の研究を通じて知り, 驚きました.