How to translate the string at local. We can use your favorite
editor/tool for translation if you work on po file. Maybe this is not a
majority use case, but you could see some patterns in the text, for
example, some of the exercises. In that case, we can use regex
replacement to effectively work on the translation.
Plan who translate which po file. Do not duplicate the task.
Choose which po file to translate. In this example, I choose the
"learn.math.cc-seventh-grade-math.pot"
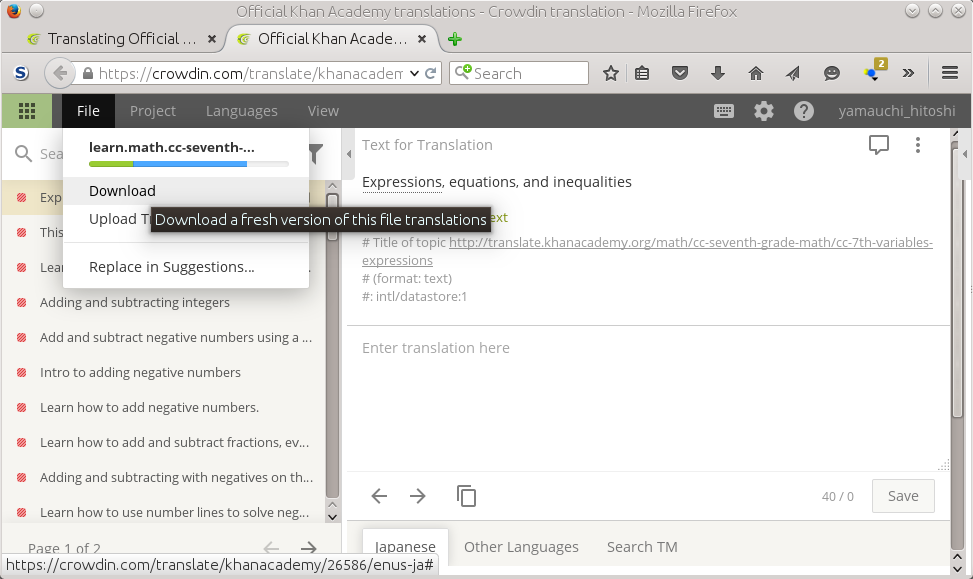
Download the po file. (Menu: File-Download)
Figure 3.1. Download a po file: choose download
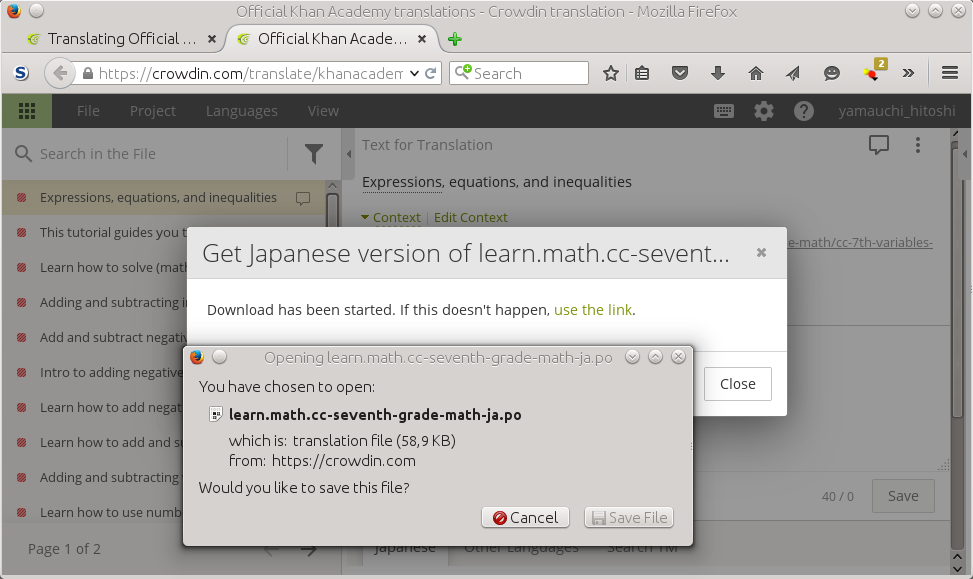
Then, save the po file to your local disk.
Figure 3.2. Download a po file: save to your local
disk
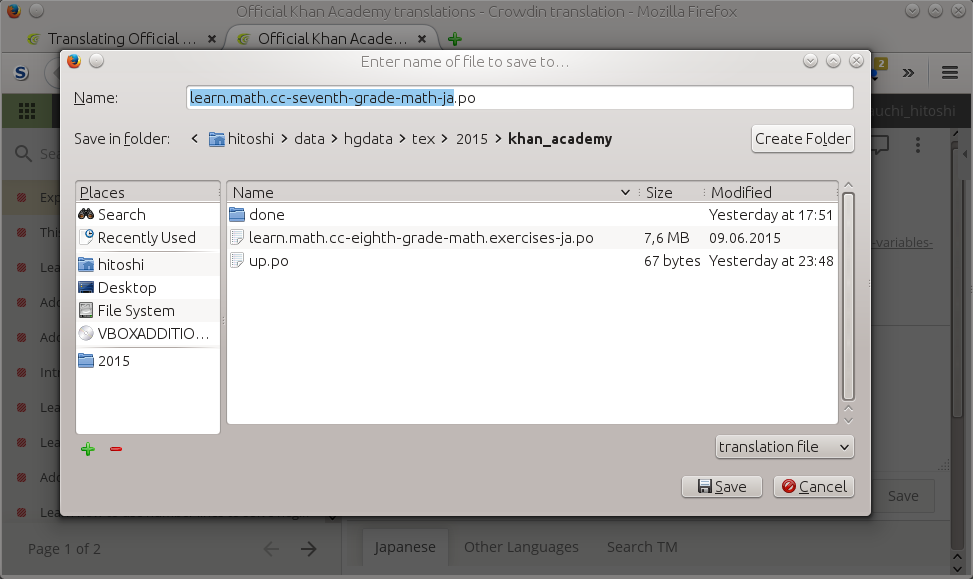
Choose the save location.
Figure 3.3. Download a
po file: Choose the save location
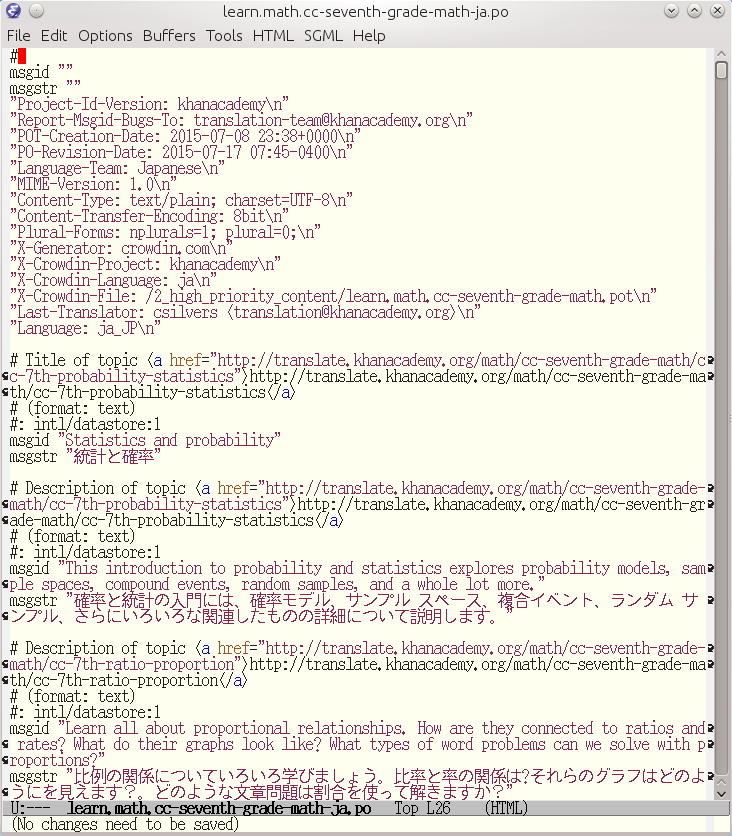
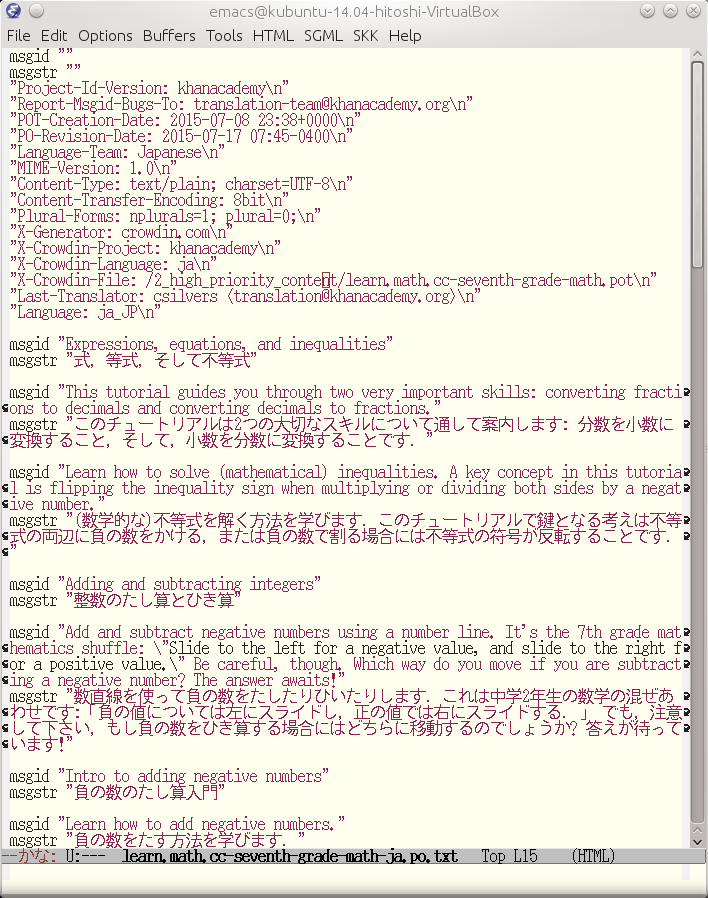
A po file is looks like the following.
Figure 4.1. downloaded po file example
You can remove the context. The context line always started with #.
Therefore, you can remove them by hand, or, for instance, use the
grep command:
The po file has a set of a pair ``msgid'' and
``msgstr''. msgid is the
identifier of which string and msgstr is each
language translation. For example, a already translated Japanese
entry is:
msgid "Fractions, decimals, and percentages"
msgstr "分数、小数、およびパーセント"
This has been already translated, so we can remove them
first. The result file looks like the following. Also please
compare the crowdin window. You see the same untranslated entries
in the both.
Figure 6.2. corresponding Crowdin window un-translated
entries only
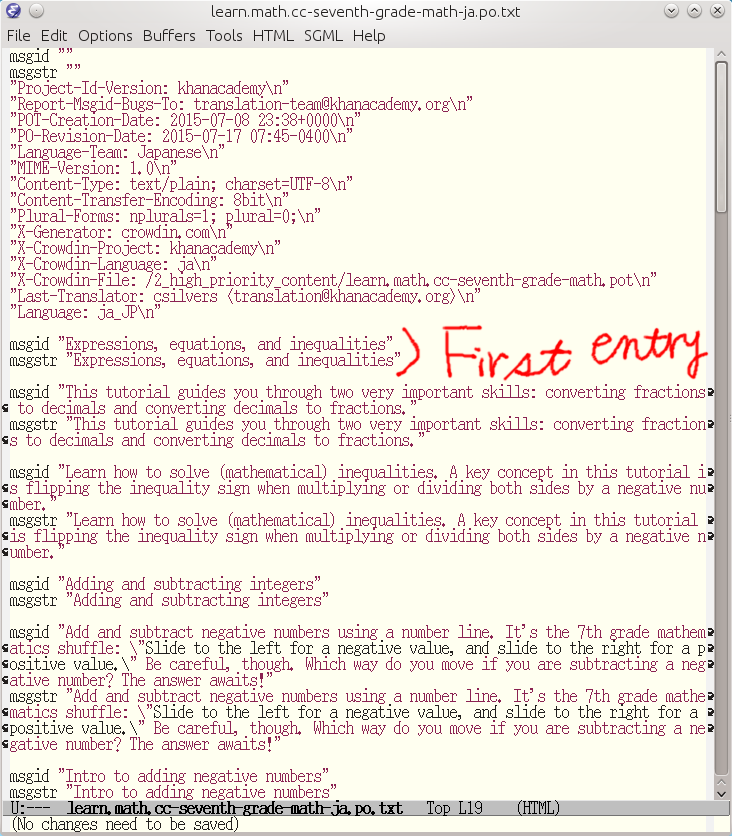
Translate only the msgstr contents.
Now you can translate with your own editor. You can translate
strings without Crowdin editor now. So we are
free from the current slowness problem.
Here is an example:
Original:
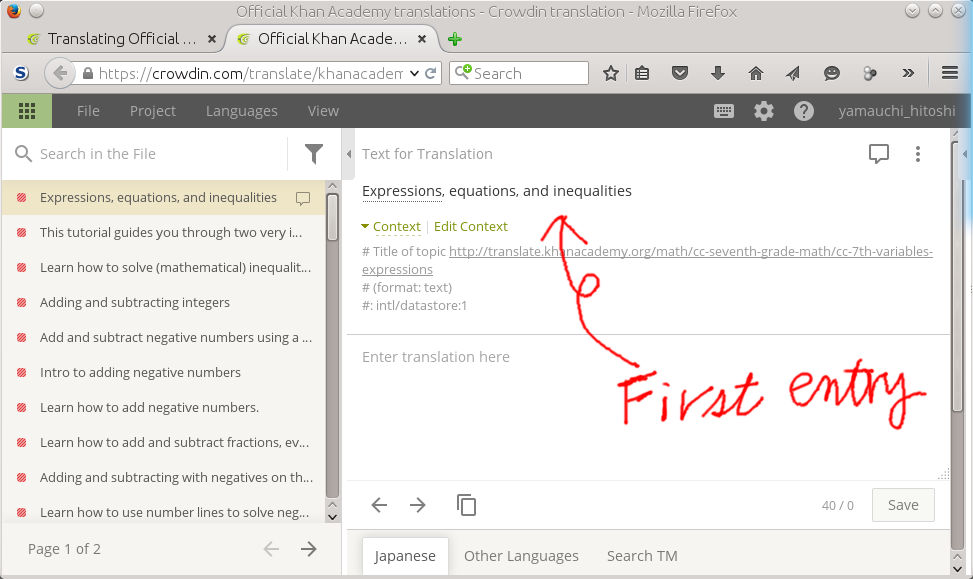
msgid "Expressions, equations, and inequalities"
msgstr "Expressions, equations, and inequalities"
Translated (to Japanese):
msgid "Expressions, equations, and inequalities"
msgstr "式,等式,不等式"
Please note, the msgid line has no change.
The below is translated po file.
Figure 7.1. Translated po file
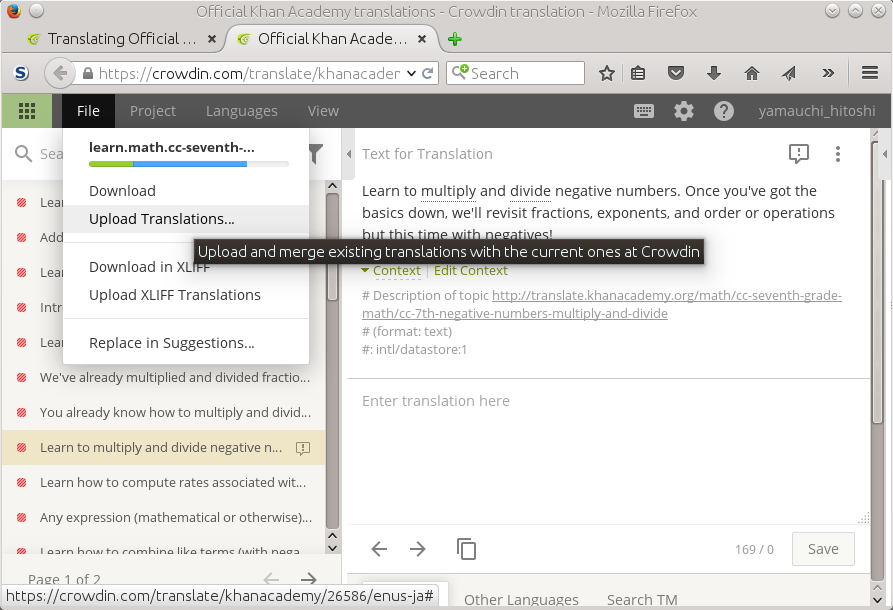
Upload the po file.
Note: translated po file's file extension must be
.po.
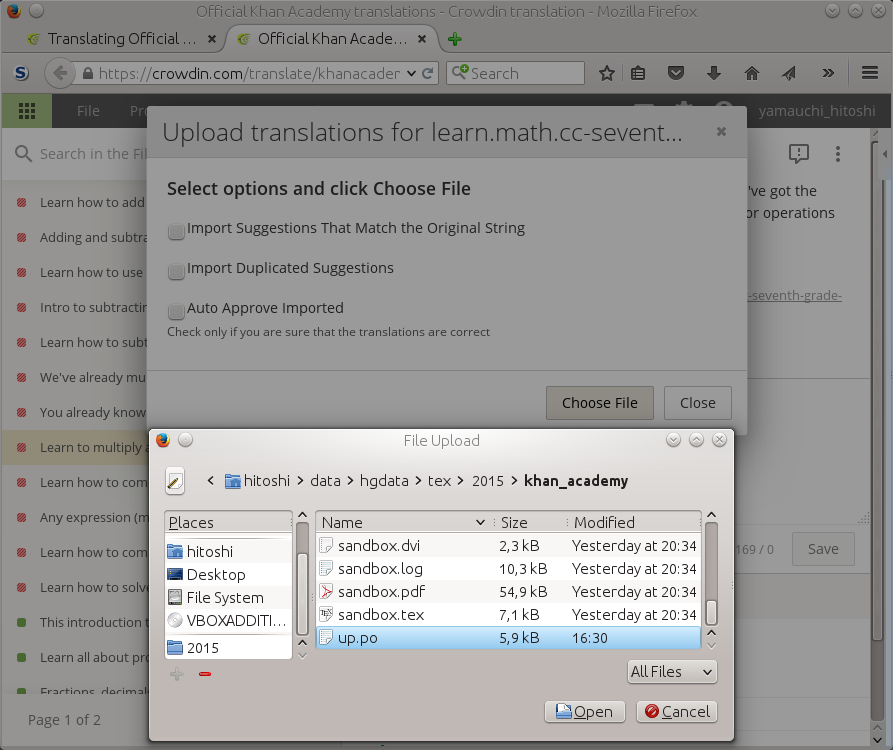
You can also upload the file partially. You need the header and
some of the (msgid, msgstr) entries.
Figure 8.1. Upload the po file 1
Figure 8.2. Upload the po file 2: choosing the upload
file.
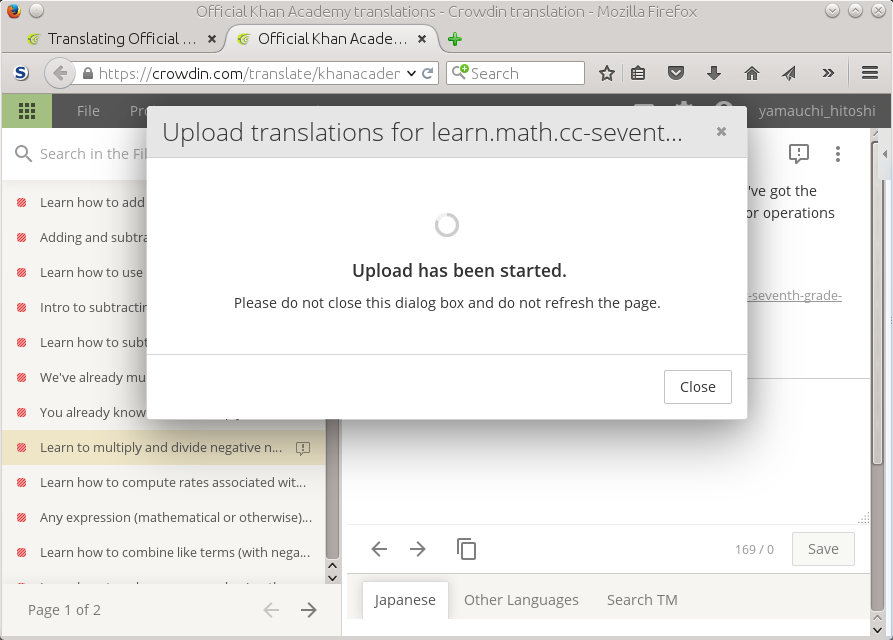
Figure 8.3. Uploading the po file: (This might take
long.)
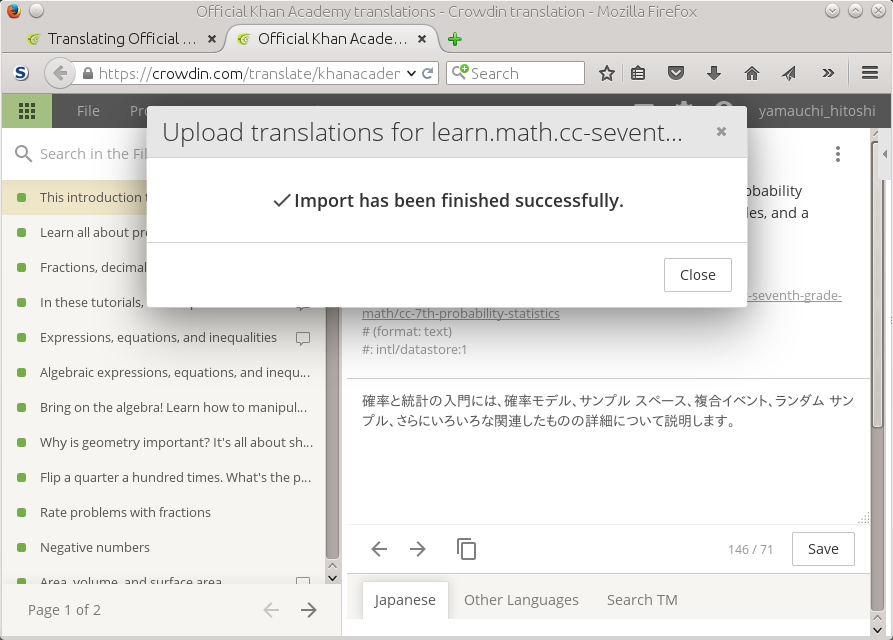
Figure 8.4. Finished upload the po file.
Check the uploaded strings.
Use the proofread mode, you can check the uploaded entries are
correct or not. When you remove the double quote, then upload would
fail. But, such entries are usually just not translated.
Here is the project page. You see the
learn.math.cc-seventh-grade-math-ja.pot entry is now 100%
Figure 9.1. Uploaded all the entries.
Figure 9.2. Proofread with uploaded entries first.
In this way, the main task, at least the translation part has no
waiting time.
Suggested solution for the crowdin slowness problem
It seems using non-O(n) algorithm to update the database. Since when
the data size was smaller, it worked OK, but some data size exceeded,
suddenly worked too slow. (But this is just an hypothesis.)
Solution suggestion
Use O(n) algorithm (the right solution)
Do not check the inter-file dependency. We have almost none,
except Glossary file. This should be handled separately.
However, this will take time I presume. So, here is workaround
solution.
Remove (at least partial) 4_low_priority entries.
This reduce the data size and give some time to fix.
YouTube transcript to srt file converter
Introduction
Some of the Khan academy English subtitles are only available on
YouTube, not on amara. Here the problem is we usually need a srt file
for our translation work flow. However, YouTube provides Transcript as
shown in the image below, and you can copy and paste as text.
YouTube Transcript Example
If we have a converter from this YouTube Transcript text to srt file
format, we can translate the file and upload to amara.
This is a python script to do
that.New BSD
License. Anyone can use this script freely. I suggest to save this
python script as 'txt2srt.py' since the following usage refers this
script as 'txt2srt.py' (to make the explanation easier).w
A sample input/output of the script.
Input (YouTube Transcript format)
Output (srt format)
0:00Voiceover: The title of Thomas Piketty's book
0:02is Capital in the 21st Century.
0:04It's probably worth having a conversation
0:06about what capital is.
→
1
00:00:00,000 --> 00:00:02,000
Voiceover: The title of Thomas Piketty's book
2
00:00:02,000 --> 00:00:04,000
is Capital in the 21st Century.
3
00:00:04,000 --> 00:00:06,000
It's probably worth having a conversation
4
00:00:06,000 --> 00:00:10,000
about what capital is.
How to use the script.
Copy and paste 'Transcript' text from YouTube to a text
file. (e.g., trans.txt)
Run the script as following (Note: please use python 3) txt2srt.py --infile trans.txt > trans.en.srt
Known issues
YouTube's transcript has only minutes:seconds information,
therefore, the time precision is limited. Unfortunately, I cannot
fix this since there is no information.
Sometimes I cannot see the Transcript option, it seems depends on
the video and browser.
Sometimes I found different result of transcript copy and paste. In
that case, please transform to that the time and the contents is in
one line.
Semi automate subtitle timing generation (srtconv use
case 1)
Timing generation of a subtitle is time consuming work. If we can
automated, or at least semi-automated, it could save time. I tried the
following method and save up to half of the time so far with my work
flow.
My case, I work on a srt file. I use amara or camtasia studio for subtitle timing generation. But this
is basically a manual work. I have already dubbed video and translated
text. So, I discuss with some friends and research a subtitle timing
generation, then, I got a following idea.
Use YouTube transcript mechanism to generate the srt file.
So the basic technology is YouTube's transcript. The YouTube's
transcript accepts a text file. And YouTube transcript sometimes cut the
original text lines and make multiple lines, so the simplest method
needs only two filters: srt to text filter, srt file subtitle line
concatenations. This is just a simple text filter.
A semi-automated subtitle timing generation work flow
Generate a text file from a srt file using srtconv.py. An example command is: srtconv.py -i input.srt -o output.srt --outtype text
Use YouTube transcript text function to generate subtitle timings.
Use amara or Camtasia to fine tune the subtitle timing.
Tips: If you have any new idea for srt file filtering, this script has a
simple srt file parser. You can use that parser as you like. The license
is New BSD
License, so you can freely use it.
Fix inconsistent subtitle timing information of a .srt
file (srtconv use case 2)
We see some srt file has the following two time information problems.
Inconsistency of time information: Sometimes we
encounter a srt file that has inconsistent time information. For
example, a srt has time inversion information (a later subtitle has
an earlier time stamp, so there is an overlap of subtitles.) Some
tools have a problem to process this kind of srt file.
Gap between the entries: The voice of most of
lecture videos are continuous. But, some srt files have many gaps.
Although some of them are pause, still usually it doesn't harm,
rather better, to show the subtitles.
srtconv.py has a option --timeline
rm_gap. This automatically fix the inconsistency and remove gaps.
But there is a limitation. The algorithm only looks up the current
subtitle line and the next one. Therefore, if the inconsistency is over
than that this program casts an error. For example,
1
00:00:04,000 --> 00:00:06,000
The first subtitle start at 4 seconds, ended at 6 seconds.
2
00:00:02,000 --> 00:00:03,498
The second subtitle start at 2 seconds, ended at 3 seconds.
The program only can change the end of first subtitle timing, and cannot
find the valid time in such case.
It is possible to write a code that keeps consistency globally, but
then, this will change the start timing of subtitle line. This is
usually not wanted. Thus, this time inversion case as in the example
should be fixed manually.
The following Figures 1 and 2 show the result of this process.
Figure 1: Subtitles have gaps and inconsistency between
lines.
Figure 2: Automatically fixed gaps and time inconsistency
between subtitle lines.
po file filter to extract untranslated entries
When a po file on crowdin has updated, you need to extract untranslated
entries. This filter pofilter
does the work. New
BSD License. Anyone can use this script freely. I suggest to save
this python script as 'pofilter.py' since the following usage refers
this script as 'pofilter.py' (to make the explanation easier).
How to use the filter.
Run the script as following (Note: please use python 3) pofilter.py content.chrome-ja.po content.chrome-ja.po.txt
Please refer help for other options.
Download captions with YouTube API
This is my use case. I need to download the English caption to
localize the Khan academy education video. But YouTube video editor
doesn't provide the download function for the captions which I don't own
(at 2018-4-22(Sun)). However, it is convenient for internationalization
volunteers to have a function to download a public captions of public
videos. But, through the YouTube API, you can download the public
video's public caption. Here is memo about that. But I am afraid to say I
am not an expert of this are and some part would be missing of the
following.
Here, my goal is to download some public caption (srt) file using a
python script.
To use the YouTube API, there is some
authentication process I should do. If you authorize a Google API use,
you have a console of it.
The above condole gives you Credentials, you need to downaload it
as a json file and file name should be client_secrets.json for
the following python caption management tool. Some functionalities
can be used without this file if you don't download files. But if
you download a file, it seems needed this at local.